This blog post will cover data silos and data duplication, as well as the concept of the single source of truth. It will then go into some real world examples and some key take aways.
What are data silos and data duplication?
A data silo is a collection of relevant data held by a team, person, department or system in your organization that isn’t fully accessible by other groups in the organization. This means data silos prevent relevant data from being shared in your organization.
Data silos can be an issue when information for the same data subject is stored in different data silos. For example, information on your members could exist in multiple different systems. Different colleagues and departments are encouraged to store data in different places with data silos, which can lead to data duplication.
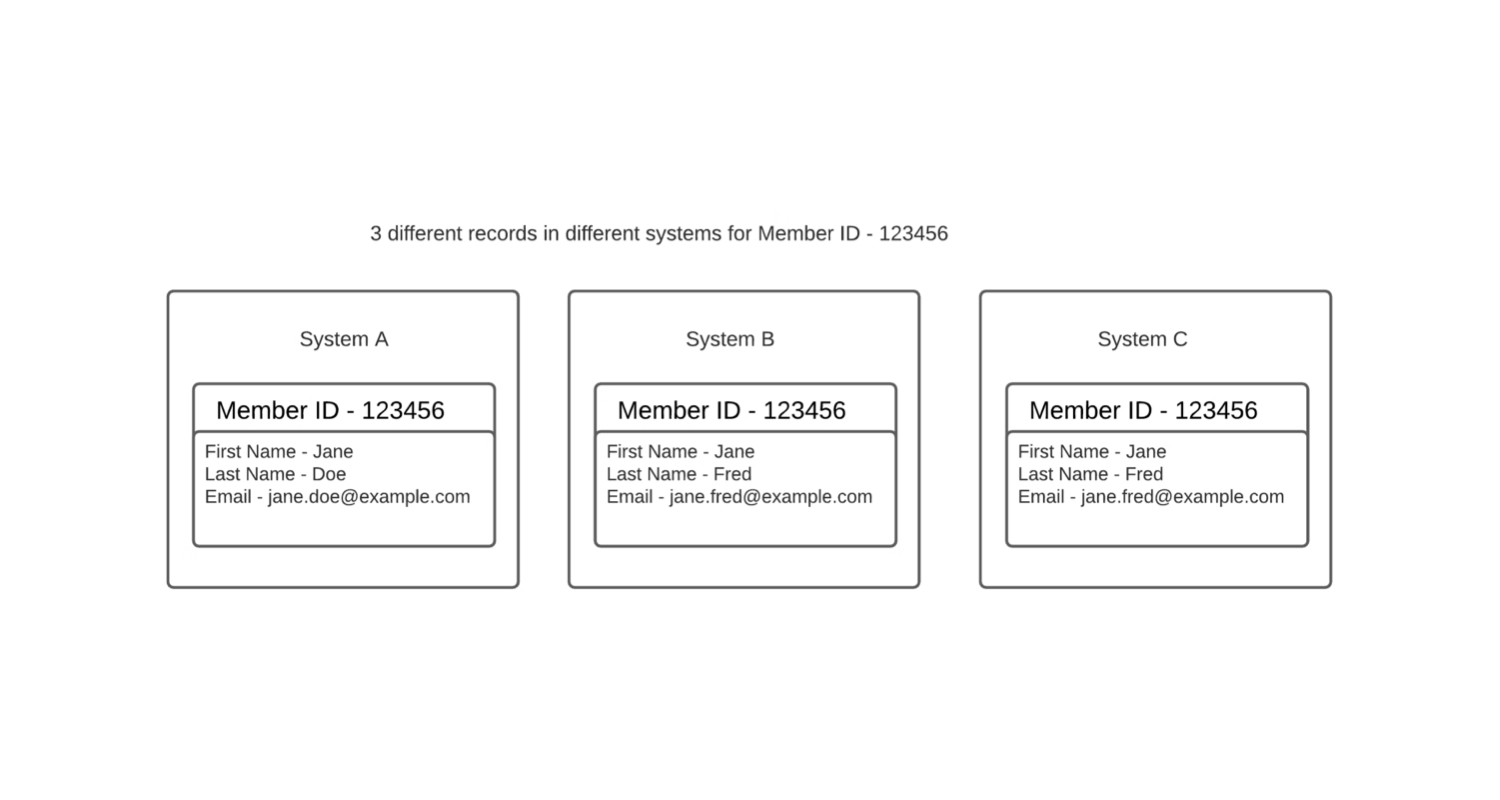
A data duplication is when the same information lives in different systems, or in the same system multiple times. An example of this is three different systems that store the same member’s email address, name and address.
Data duplication can be an issue when, for instance, three different systems have different details for the same Member ID. It means we are unsure which values are correct. Just because the first and third record is the same, it doesn’t mean that they were the last updated or most accurate records.
In another scenario, data duplication can be an issue where one system has three different member IDs. However, they are likely all the same person with potentially poor process, business logic or human error. Duplicate records could be created from these.

It’s important to break free from the risk of data silos and duplication because…
“70% of Membership Organisations also confirm that member data is used to make important decisions / validate key assumptions yet only 8.5% have actually defined and documented the meaning of key data elements and only 13% of membership bodies consider their staff to have confidence in the accuracy of available data.
– MemberWise 2021/22 Digital Excellence report

70% of Membership Organisations somewhat agree/agree there is a reliance on data to operate more effectively; only 28% agree they have all their critical systems integrated.
But why do they occur?
Data silos and data duplication often occur because of business success, organizational structure and SaaS products or specialist applications.
A growing organization is the biggest cause of data silos and data duplication. Success of a business might lead to existing systems failing to scale alongside the growth. Departments might implement new processes and application rollout in an ad hoc, less structured manner.
In any organisation, data silos occur naturally. This often mirrors the structure of an organisation’s departments. Data is collected independently by different teams within the organization for its own purpose, without a holistic central data strategy. Once a data silo occurs, data duplication often follows.
SaaS products or specialist applications are examples of powerful software applications that deliver very specific functions. These are often preferable to using a comparable product within a single behemoth system solution that is not as strong. Some data is naturally duplicated or siloed when using these tools.
There are several costs and risks of data silos and data duplication in membership organisations. The risks include a poor experience across the end-to-end customer journey. Customers could become irritated by presenting out-of-date information.
A poor customer service can also be a risk of data silos and duplication. Colleagues might respond to members without having a wider context. For example, responding to a finance query on the finance system, without realizing that the member recently complained about something.
Other risks are a reduction in the quality of data held over a period of time; assuming that incorrect information is accurate; data security; inaccurate reporting and brand reputation.
There are also costs, including inefficient use of limited internal resource, leading to a duplication of effort and additional communication. Other costs are paying for redundant IT, applications or storage costs, as well as the cost of emailing or posting.

Can data silos and data duplication be helpful?
However, intentional data silos and data duplication can also be an appropriate business decision. Data silos can be appropriate for if you have highly sensitive information, or if you have information that is only ever required for a particular group of your end users.
Data duplication can help you use the best and most cost effective or appropriate tools for different tasks. It can also be required, for example, your membership portal or website might be quicker at searching or looking up membership information if members are held locally on the website. This can lead to records being duplicated from your CRM.
There is also functionality-driven data duplication, which is when an application holds the source data might not offer a particular piece of functionality. This might mean that you need to duplicate data to a more specialist application that better fulfils your business needs.

The single source of truth
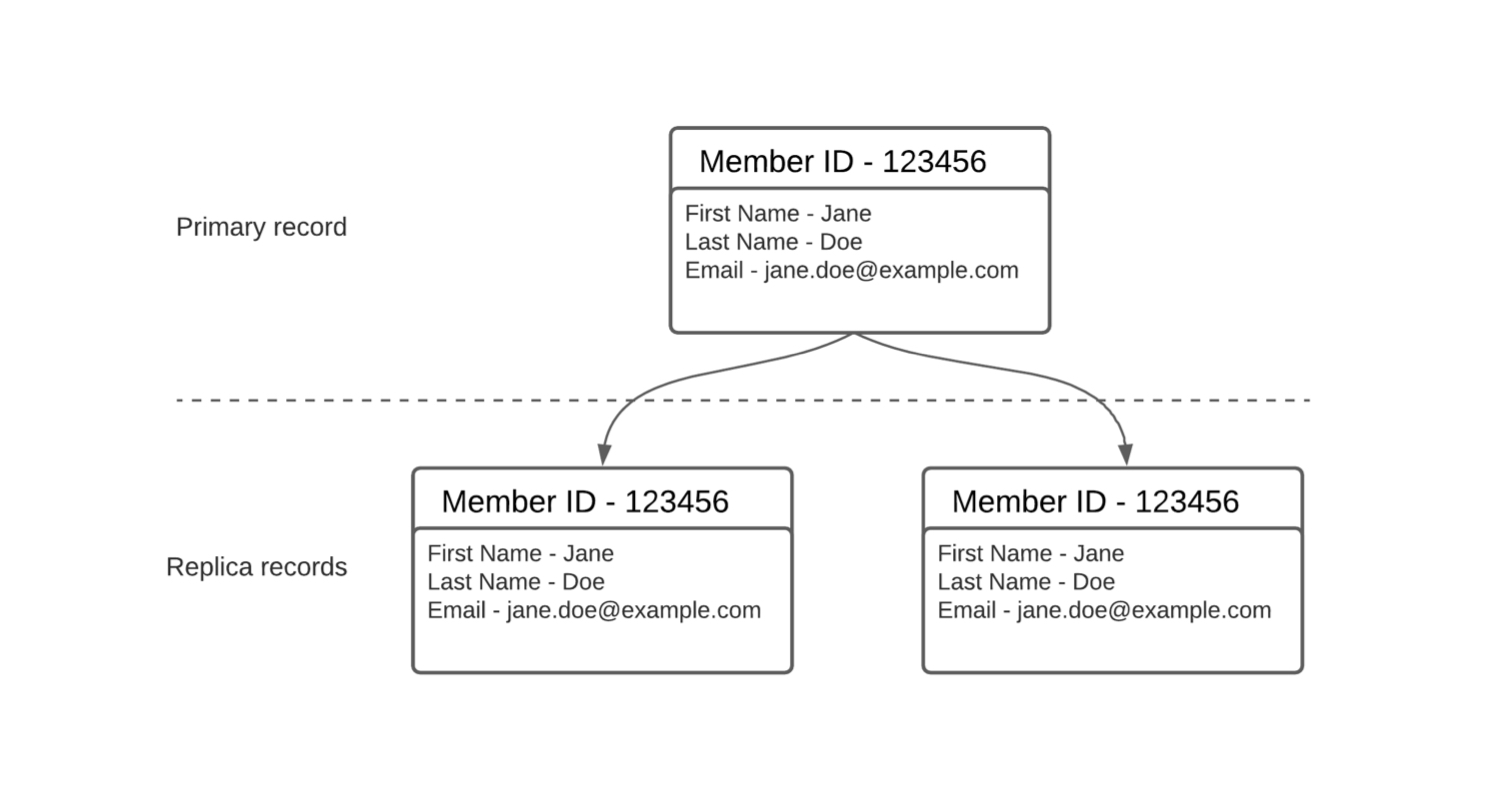
To manage unintentional data silos and duplication, the concept of a single source of truth can help. The aim of a single source of truth is to ensure that every data element is only ever edited in one place. This seeks to clearly document which system has the primary record, which holds the most up-to-date information for different data.
Once defined, the primary record can inform business processes around where data is updated and how data and information needs to flow between internal and external systems when updated.
Primary records will then become your single truth for different data elements. Other instances where the data has been duplicated will become known as replica records.
How a single source of truth can inform decisions and digital transformation
To get a holistic view, you need to list different system used within your organization. You then need to detail the different data held within them. Then, outline whether the data is read only or editable.
Spreadsheets are a good starting point for this, but there are a variety of tools you can use. You can use rows for the different systems and rows for data and highlighting. Against each system, you can define the owner – being the department or person. A headline statement for what this system is for also helps.
Keep the definition of data very high level, such as membership information. Once completed, you should have an initial picture of how many systems or applications are holding high level comparable data.
Ensure the list is cross referenced with your finance team, in case you are still paying for systems that no one uses anymore.
Once you’ve got a holistic view, you may immediately be able to make business decisions. After this, you can do a more detailed deep dive, adding data fields such as member email, member first name and then repeat the exercise.
With a deep dive, we are trying to discover a number of things. This includes understanding what systems are updating records; review system access rights; ensuring people have appropriate access to update primary records; try to reduce people who have access to the systems that hold replica records.
We are also trying to review the capability of the systems; document internally to make it clear where primary records are held; and train colleagues and raise awareness to inform and encourage collaboration.
There are some more complex, subsequent steps you can follow. You can automate syncing replica records from primary records; directly query primary records (and write back to them); reduce unnecessary duplication and silos; restrict access.
Scenario One
Let’s move onto some real-world examples, such as email marketing. A central CRM or AMS system stores the primary records, but there is a more cost effective or better email marketing tool that we want to use.
Data considerations for this includes which system holds the primary record or email, marketing preferences or opt-in or out.

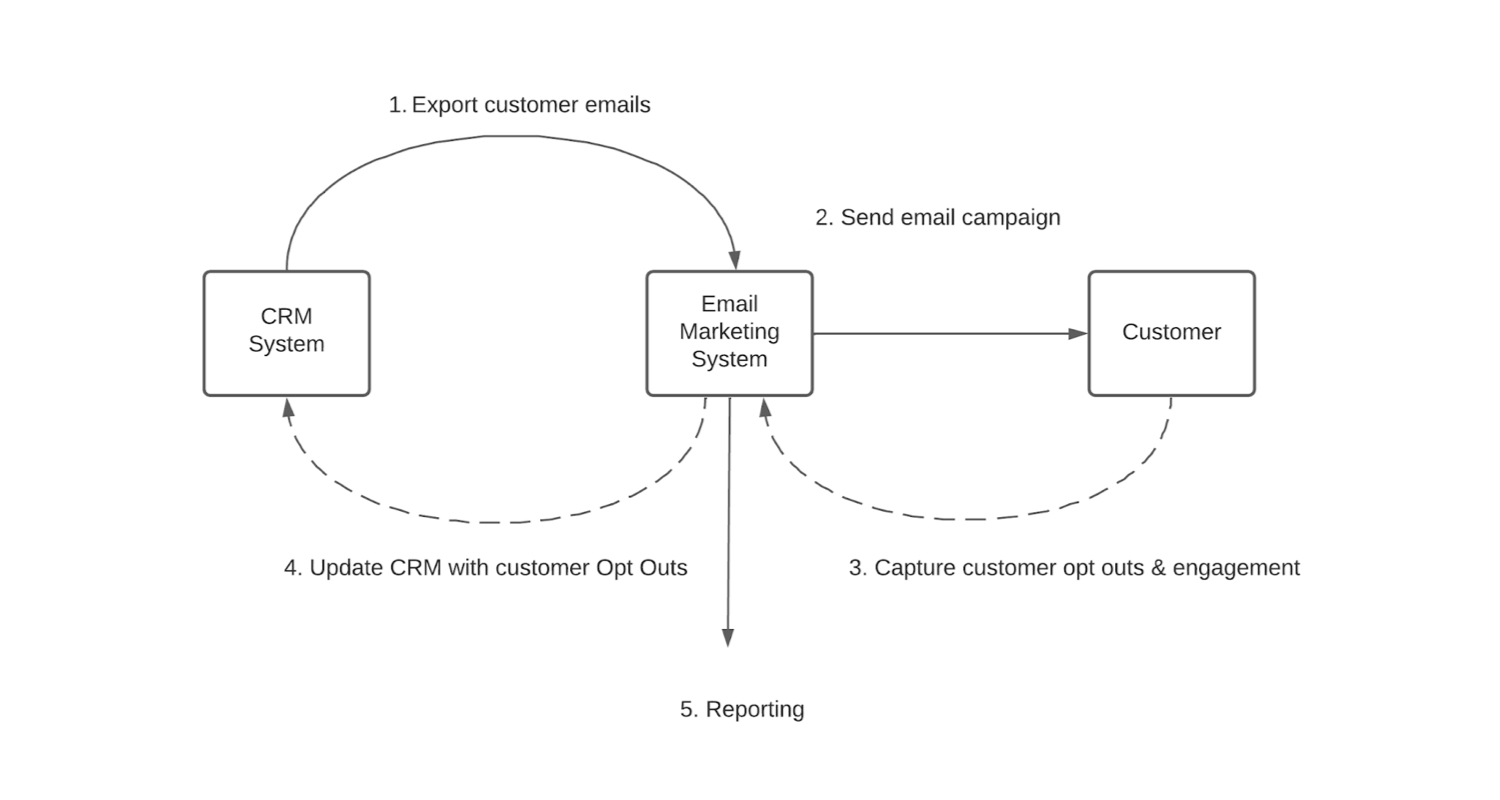
However, there is no one size fits all approach.
- Option one – could be to capture opt outs in the email marketing tool and export them back to the CRM to update the master record.
- Option two – could be to unsubscribe options in the email campaign link to a form that writes back into CRM. If no other mechanism was available to the user to unsubscribe
- Option three – could be used to capture the email marketing tool – the tool prevents anyone who is already unsubscribed from being sent another email.
Scenario two
Another scenario is when we want to have searchable member events on our website. This would let members search based on distance, which isn’t supported by the membership CRM that houses primary event records. However, the CRM or AMS event search might be too slow to query for the website, taking 10 seconds.
You would need to consider the primary records of events that are held in CRM or AMS. It’s also really important to consider that the website has up-to-date availability of spaces or stock.
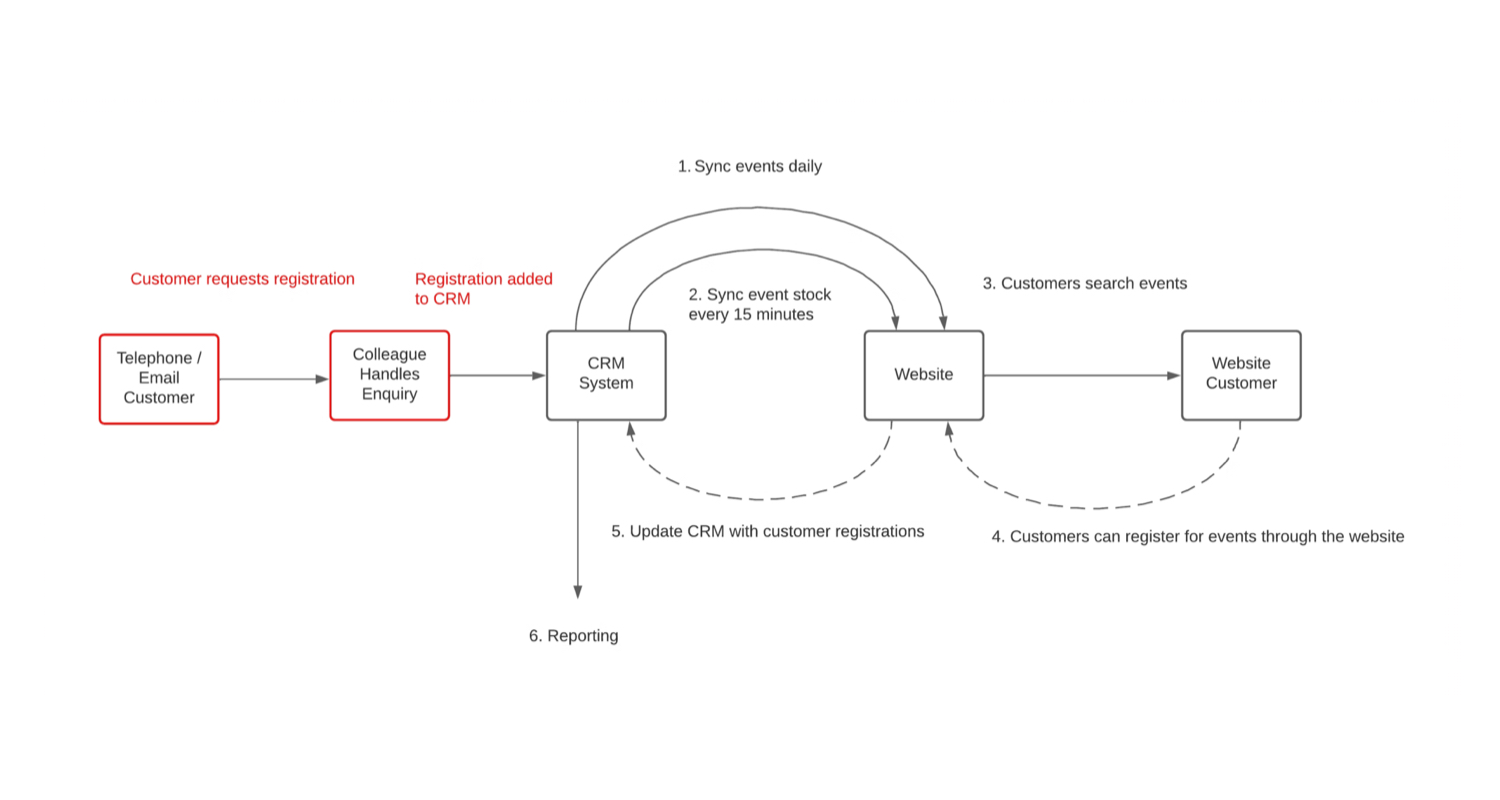
There are several advantages of this approach. It will ensure user experience is not compromised by the speed of feature limitations of the CRM API. We have a quick-loading events search that supports distance searching.
The CRM always has the latest information for orders and stock. This means if any telephone enquiries come in, they don’t have to cross reference with the website.
If the website stores replica records of the order history, any changes that are made against the primary record on the CRM will automatically update the website.
Outcomes and key takeaways
In conclusion, it’s good to have an understanding of data silos and duplications, how they can occur and the risks and costs associated.
It’s important to have a holistic view of the data within your organisation to define the single source of truth. Then, you can inform and educate your colleagues as well as future projects and digital transformation.
You should reach out to experts such as Spindogs where additional support is needed.
Data silos and duplication can be helpful for businesses if they are intentional, but unintentional silos and duplications are where the issue rises.